How to Choose the Right Database
Selecting the right database is one of the most consequential architecture decisions in any software initiative. It affects performance, scalability, consistency, operational complexity, cost, and the long-term ability of the system to evolve. There is no single database that is universally best for all situations. The right choice depends on the nature of the application, the structure of the data, and the operational and transactional requirements that the solution must satisfy.
A sound database selection process should therefore begin with the application’s real needs rather than with vendor popularity or technology trends. The key is to translate business and technical requirements into a clear set of evaluation criteria. The accompanying diagram provides a practical view of these criteria and shows how different database technologies tend to align with different architectural needs.
Start with the Application Requirements
The best way to get started is to define the application requirements by answering a focused set of questions. These questions help narrow the field and distinguish which database families are more suitable for the solution.
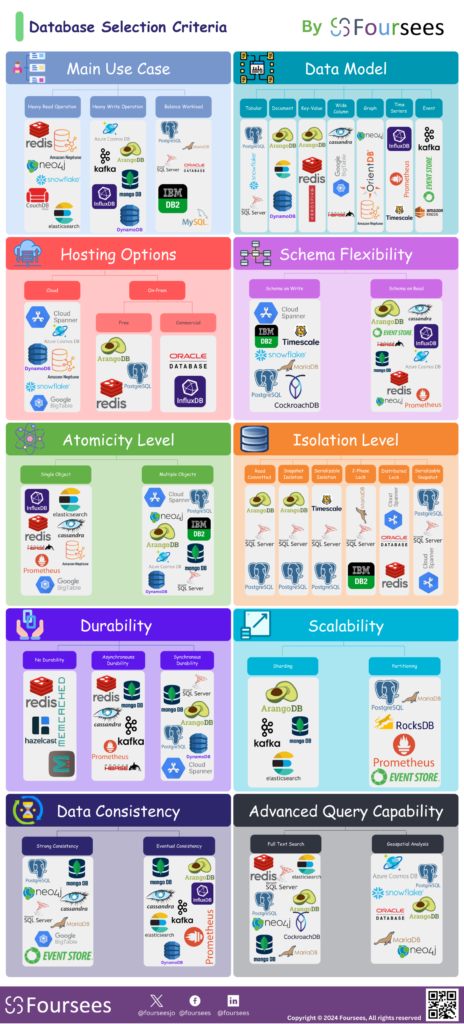
1. Main Use Case
The first question is about the nature of the workload. Is the application primarily read-intensive, write-intensive, or does it need to support a balanced mix of both? This matters because different databases are optimized for different access patterns. Some perform exceptionally well in heavy-read scenarios such as caching, search, analytics, or content delivery. Others are designed for heavy-write workloads such as event ingestion, telemetry, messaging, or high-volume transaction capture. Traditional relational databases often handle balanced transactional workloads well, while specialized engines may outperform them in extreme read or write scenarios.
Understanding the primary use case prevents the selection of a database that works in principle but becomes a bottleneck under actual production load.
Heavy-read operations
Examples:
- Redis
- Elasticsearch
- Neo4j
Heavy-write operations
Examples:
- MongoDB
- DynamoDB
- InfluxDB
Balanced workload
Examples:
- PostgreSQL
- SQL Server
- MySQL
2. Data Model
The second question concerns the type and structure of the data. Is the data tabular, document-based, key-value, wide-column, graph, time-series, or event-oriented? The data model should strongly influence the database choice. Relational databases are well-suited to structured tabular data with strong relationships and transactional requirements. Document databases are often a strong fit for semi-structured and evolving data models. Graph databases excel when relationships between entities are central to the problem. Time-series databases are optimized for chronological measurements and metrics. Event stores are better aligned with append-only event-driven systems.
Choosing a database whose native model matches the shape of the data usually results in simpler design, better performance, and lower implementation complexity.
Tabular
Examples:
- PostgreSQL
- SQL Server
- MySQL
Document
Examples:
- MongoDB
- ArangoDB
- Azure Cosmos DB
Key-value
Examples:
- Redis
- DynamoDB
- Aerospike
Wide-column
Examples:
- Cassandra
- Google Bigtable
- HBase
Graph
Examples:
- Neo4j
- Amazon Neptune
- ArangoDB
Time-series
Examples:
- InfluxDB
- TimescaleDB
- Prometheus
Event-oriented
Examples:
- Kafka
- EventStore
- Amazon Kinesis
3. Hosting Options
The third consideration is hosting preference. Will the solution run on-premises or in the cloud? Is the target environment constrained by compliance, latency, sovereignty, or existing infrastructure strategy? What budget is available? Hosting preference directly affects the feasible database options. Some databases are available as fully managed cloud services, reducing operational overhead. Others are better suited for self-managed or enterprise-controlled environments. In some cases, the decision is influenced less by technology and more by regulatory constraints, internal platform standards, or licensing costs.
Budget also matters. The total cost is not limited to licenses; it includes hosting, operations, support, backup, monitoring, scaling, and administrative effort.
Cloud
Examples:
- Cloud Spanner
- DynamoDB
- Azure Cosmos DB
On-prem
Examples:
- PostgreSQL
- Redis
- ArangoDB
Commercial / enterprise-oriented
Examples:
- Oracle Database
- DB2
- Snowflake
4. Schema Flexibility
Another important question is how the application handles data structure and schema. Does it require strict schema enforcement, or does it benefit from schema flexibility? Applications with highly structured data and stable business rules often benefit from schema-on-write approaches, where validation and structure are enforced early. Applications dealing with variable, semi-structured, or rapidly evolving payloads may benefit from schema-on-read or more flexible document-oriented models. This decision affects not only development agility, but also data quality, governance, and downstream integration.
Schema on write
Examples:
- PostgreSQL
- Cloud Spanner
- CockroachDB
Schema on read / flexible schema
Examples:
- MongoDB
- Cassandra
- ArangoDB
5. Atomicity Level
Atomicity determines whether a set of operations succeeds as a single unit or fails as a whole. The key question is whether the application performs updates on a single object at a time or frequently needs to update multiple objects together in one consistent transaction. If the business process requires multiple data changes to succeed or fail together, then transactional support becomes a major selection criterion. This is particularly important in financial systems, order processing, inventory, and other domains where partial updates are unacceptable. Some databases provide strong multi-record transactional guarantees, while others prioritize performance and scale over full transactional breadth.
Single-object dominant updates
Examples:
- Redis
- Cassandra
- InfluxDB
Multiple-object transactions
Examples:
- PostgreSQL
- SQL Server
- Cloud Spanner
6. Isolation Level
Isolation concerns how concurrent operations interact with each other. Can different transactions run in parallel with some acceptable overlap, or must the system prevent anomalies such as dirty reads, non-repeatable reads, or phantom reads? This is a critical architectural decision because higher isolation levels increase correctness guarantees but can reduce concurrency and performance. Lower isolation levels improve throughput but may allow certain anomalies. The right choice depends on business tolerance. Some applications can tolerate temporary overlap or eventual reconciliation. Others require strict transaction isolation to preserve correctness.
Read committed
Examples:
- PostgreSQL
- SQL Server
- ArangoDB
Snapshot / MVCC-style isolation
Examples:
- PostgreSQL
- SQL Server
- CockroachDB
Serializable isolation
Examples:
- PostgreSQL
- Cloud Spanner
- Oracle Database
7. Durability
Durability defines whether committed data must be permanently retained once the operation succeeds, even in the event of crash, failure, or outage. The essential question is whether the application can tolerate even a slight possibility of data loss. In some systems, such as observability pipelines or temporary caches, limited risk may be acceptable in exchange for speed and scale. In others, such as core financial records, compliance logs, or legal evidence trails, durability is non-negotiable. This criterion often distinguishes lightweight high-speed data stores from databases designed for mission-critical persistence.
Lower durability tolerance acceptable
Examples:
- Redis
- Memcached
- Hazelcast
Asynchronous durability
Examples:
- MongoDB
- Kafka
- Cassandra
Strong synchronous durability
Examples:
- PostgreSQL
- SQL Server
- Cloud Spanner
8. Scalability
Another major factor is growth. Will data volume, transaction rates, user concurrency, or geographic distribution increase significantly over time? If scalability is a major requirement, the architecture must consider how the database scales: vertically, horizontally, through sharding, through partitioning, or through distributed clustering. Some platforms scale elegantly for read-heavy patterns, while others are better for massive write throughput or global distribution. Scalability should be evaluated not only for technical feasibility, but also for operational complexity. A database that scales in theory may still be difficult to manage at scale in practice.
Sharding
Examples:
- MongoDB
- Elasticsearch
- ArangoDB
Partitioning
Examples:
- PostgreSQL
- MariaDB
- EventStore
Distributed scale
Examples:
- Cloud Spanner
- Cassandra
- DynamoDB
9. Data Consistency
For distributed and replicated systems, consistency becomes a major design question. Must all nodes reflect the latest committed state immediately, or can the application tolerate eventual consistency and reconcile temporary differences? Strong consistency is essential in some domains, especially where correctness and immediate accuracy are critical. Eventual consistency can be acceptable in many large-scale distributed applications, particularly where high availability and performance are more important than immediate synchronization. This is not merely a technical preference; it is a business rule expressed in architectural form.
Strong consistency
Examples:
- PostgreSQL
- SQL Server
- Cloud Spanner
Eventual consistency
Examples:
- Cassandra
- DynamoDB
- Elasticsearch
10. Advanced Query Capability
Finally, it is important to examine the querying needs of the application. Does the solution require full-text search, geospatial analysis, graph traversal, time-series aggregation, or other specialized query patterns? Not every database is equally capable in these areas. Some are optimized for transactional processing but weak in advanced search. Others offer powerful indexing and specialized query engines for search, analytics, or spatial use cases. When these capabilities are central to the application, they should not be treated as secondary considerations. Choosing a database without evaluating advanced query needs often leads to later architectural workarounds, secondary tools, or costly redesign.
Full-text search
Examples:
- Elasticsearch
- PostgreSQL
- MongoDB
Geospatial analysis
Examples:
- PostgreSQL
- Azure Cosmos DB
- Oracle Database
Graph traversal
Examples:
- Neo4j
- Amazon Neptune
- ArangoDB
Time-series aggregation
Examples:
- InfluxDB
- TimescaleDB
- Prometheus
The Real Goal: Fit-for-Purpose Selection
The database selection process is not about identifying the most powerful product in absolute terms. It is about identifying the most appropriate technology for the application’s requirements. A system with strong ACID requirements, structured data, and strict consistency needs may point toward a relational database. A content-rich platform with variable payloads may be better served by a document database. A recommendation engine or social relationship model may benefit from a graph database. High-ingestion telemetry platforms may favor time-series or event-oriented solutions. Search-heavy systems may require technologies with strong indexing and retrieval capabilities.
In many enterprise environments, the answer is not a single database at all, but a polyglot persistence strategy in which different databases are used for different workloads. The key is to apply this intentionally, not accidentally.
Using the Diagram as a Decision Framework
The provided diagram is useful because it organizes database selection into practical decision dimensions:
- workload characteristics
- data structure
- deployment model
- schema behavior
- transactional behavior
- concurrency handling
- persistence guarantees
- growth patterns
- consistency expectations
- specialized query needs
Taken together, these criteria form a structured way to assess candidate technologies and avoid shallow selection based only on familiarity or market momentum.
Final Thought
Choosing the right database is not a purely technical comparison exercise; it is an architectural alignment exercise. The right database is the one that best supports the application’s workload, data model, transaction profile, deployment constraints, and long-term scalability goals. By starting with the right questions and using a criteria-based evaluation approach, organizations can make database decisions that are more defensible, more scalable, and far better aligned with business and system needs.
Ready to apply these insights?
Our architects are ready to help you design the path forward.
Book a Consultation